SPI 통신 특징 및 다른 통신(UART, I2C와의 비교
SPI 통신 : Serial Peripheral Interface 통신

- UART와 같은 직렬 통신 방식 중 한 가지
- 동기식 통신 : SCLK을 이용하여 데이터를 송수신하므로 장치 간의 동기화 필요
UART는 비동기 신호, CLK신호가 없음 // I2C는 동기 신호
- 마스터, 슬레이브 구조 : 한 개의 마스터 장치가 여러 개의 슬레이브 장치를 제어
확장성이 좋음 , 반면 UART는 1대1 통신이라 확장성이 그렇게 좋지 않음
- 다중 장치 지원 : 하나의 마스터 장치가 여러 개의 슬레이브 장치와 통신
- 양방향 통신 가능
- 연결관계 : UART는 1대1, SPI는 1대N, I2C도 1대N
- 라인수 : UART(tx, rx),
SPI(MOSI, MISO, SCLK, CS),
I2C(SCL, SDA)
- 이중통신 : UART(tx보낼 때 rx, rx할 때 tx 동시 가능 -> 전이중 통신(Full Duplex))
SPI(MOSI나갈 때 MISO 들어옴 -> 전이중 통신(Full Duplex))
I2C(반이중 통신(Half Duplex))
- Speed : UART -> 느리다 비동기 통신이라 속도가 빨라지면 에러가 높아짐
SPI -> 3개 중에 빠르다(UART, I2C 보다) 왜냐하면 동기이면서 Chip Select를 하고 해당 CLK에 맞추어 막 보내도 됨)
I2C -> SPI보다 느리다 (주소와, Data를 하나의 선으로 다 해결, data를 보낼 때 디바이스 주소를 줘야 함)
하지만 현장에서는 I2C가 현장에서 SPI보다 더많이 쓰임 -> 선 가닥이 2개임, 연결하기가 사용자 입장에서 좋다
- Digital 회로 개발자 : UART -> Simple
SPI -> Simple
I2C -> Complex ( 다른 2개에 비해 복잡, 주소도 봐야하고 read신호 write신호 판별해야 함)
만들어져있는거 쓰는 입장에서는 I2C가 편함
속도가 필요할 때는 SPI, 속도는 좀 느려도되고 Simple한거 필요할 때는 I2C
우리가 설계할 SPI 통신은 1MHz로 통신을 할 것임
100MHz 의 system CLK을 사용하므로
SCLK를 만들기 위해선 100번의 카운트를 이용해야 함
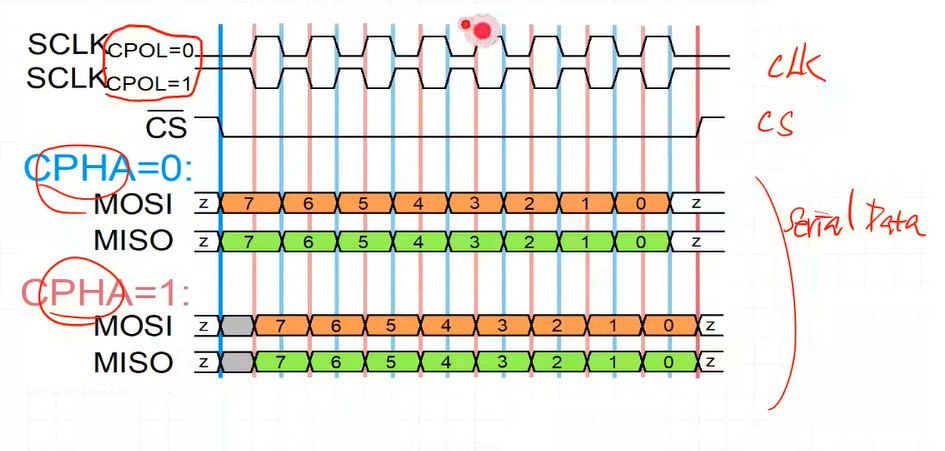
CLK polarity : CPOL = 0면 SCLK이 0부터 시작
CLK phase : 첫 번째 edge 아니면 두 번째 edge에서 시작하느냐
우리가 우선 설계하는 것은 CPOL = 0, CPHA = 0으로 구현

edge를 기준으로 봤을 때(Master 기준)
rising edge일 때 들어오는 신호(MISO)를 sampling 하겠다.
1. Master

Start 신호를 받으면 Master에서 8bit tx_data를 temp에 담아옴

위 코드는 Master에서 작성된 코드인데 SCLK의 rising edge일 때 MISO를 읽어오는 것을 볼 수 있음.
MISO는 Slave가 보내주는 데이터로, Master가 MISO 데이터를 중간지점에 읽을 수 있게 Slave를 설계 함.
(50번 카운트 하면 sclk는 rising edge일 때 임)

한번 더 50번 카운트 하면 sclk는 falling edge일 때인데
이 때 temp_tx_data_reg를 왼쪽으로 1bit shift해서 바꾸어 줌

MOSI는 다음과 같이 temp data의 MSB로 할당 되어 있으므로 SCLK의 falling edge일 때 MOSI가 바뀌게 됨
2. Slave

위 코드는 Slave에서 작성된 코드로 SCLK의 rising edge일 때 MOSI를 읽어오는 것을 볼 수 있음.
MOSI는 Master가 보내주는 데이터로, Slave가 MOSI 데이터의 중간지점에서 읽을 수 있게 Master를 설계 함
1.Master의 'MOSI 바뀌는 타이밍' 그림을 보면 falling edge일 때 MOSI를 바꾸고 있음 따라서 SCLK의 rising edge
일 때 Slave에서 MOSI를 읽으면 MOSI의 중간 지점에서 값을 읽을 수 있음

위 코드는 Slave에서 작성된 코드로 SCLK의 falling edge일 때 MISO를 내보내고 있음.
그럼 Master에서 rising edge 일 때 값을 읽어 올 수 있음

MISO는 다음과 같이 할당되어 있음.
Chipselect(negative 방식)이 되어야만 동작을 할 수 있음.
이렇게 작성한 코드가 반드시 정답은 아님
사람마다 구현방식이 다를 수 있다

rx_data = {rx_data[6:0], MISO} 상승엣지가 발생을 하면 MISO에서 들어온 값을 읽겠다.
시뮬레이션 분석

aa라는 것은 8'b1010_1010임
상위비트 먼저 나가므로 MOSI도 1010 1010 이 순서로 나감
CPOL 반영


cpol = 0이면 rising edge일 때 값이 변경
cpol = 1이면 falling edge일 때 값이 변경
CPHA 반영


CPOL = 0 이고
CPHA가 0이면
첫 번째 edge, 즉 rising일 때 샘플링을 함
CP0인 구간은 SCLK가 0일 때임
하지만
CPOL = 0 이고
CPHA가 1이면
두 번째 edge, 즉 falling일 때 샘플링을 함
CP0은 SCLK이 1 일때 임
즉 서로 반주기 차이가 있어서 설계를 어떤식으로 해야할 지 고민을 해야함

CPOL = 0 이고, CPHA = 0 일 때 언제 SCLK가 1일까 생각을 해보면
state_next가 CP1이고 CPHA가 0일 때 SCLK가 1임
CPOL = 0 이고, CPHA = 1 일 떄 언제 SCLK가 1일까 생각을 해보면
state_next가 CP0이고 CPHA가 1일 떄 SCLK가 1임
상태에 따라 sclk 발생 : r_sclk = (state_next == CP1 && ~CPHA) || (state_next == CP0 && CPHA)
정리하면 CPHA가 0일 떄 SCLK가 언제 1이되는지, CPHA가 1일 때 언제 SCLK가 1이되는지 생각 해보면 됨
왜 state가 아니고 state_next일때를 기준으로 잡을까?
-> state_next = CP1이라고 하면 실제로 state가 CP1이 되어도 다음 edge전까지는 state_next도 여전히 CP1이기 때문
->

구현을 위해 기존 r_sclk를 reg에서 wire로 바꾸어주고 always문 안에 전부 주석 처리

CP_DELAY도 새롭게 상태 추가해줌

cpha에 따라 반주기 delay가 생기는지 결정되므로 위와 같이 변경
시뮬레이션 결과


state개수를 보면 아래(cpol = 0, cpha = 1)인 경우 state 1(CP_DELAY)가 추가되어 17개의 state가 있음

MODE 3을 보면 state가 1이되어 delay가 생긴 것을 확인 가능
SPI SLAVE 예제
slave는 보통 cpha = 0, cpol = 0사용
slave는 cpha하고 cpol을 설정하는 값이 없음, 그 설정은 master가 정해주는 것
slave는 대부분 rising edge에서 동작하는 디바이스들이 많음


IDLE 상태에 있다가 address data가 들어옴(1byte) 그러고 나면 data를 받을 수 있는 data 상태가 됨.
쓰기도 하지만 읽기도 동시에 일어난다.'
현재 SPI는 메모리에 접근하는 구조이니깐 우선 address가 필요함
따라서 address를 먼저 보내고 그 다음 data가 오는 구조임
따라서 현재의 protocol은 사용자가 의도적으로 full-duplex 기능을 안쓰고 있는 것 즉, 동시에 읽고 쓰기를 하는 구조가 아님
레지스터가 여러개 있을 때 master에서 어떻게 값을 줘야 할까?

cs = 1 이었다가
data를 주면서 0으로 떨어지고
처음에는 address를 줌 . 그리고나서 data를 주는데 이 때 address가 자동으로 1 증가함
이어서 data를 주면 address+1한곳에 data를 준다

읽고 쓰기가 동시에 일어나니깐 읽으려면 값이 무조건 나가야함
그래서 읽을 때 더미 byte를 보내는 경우가 있음. 그러면 더미 데이터가 slave에 쓰이는게 아닌가?
-> 더미 데이터를 write하지 않게 해야 함
MSB가 1이면 write , 0이면 read

slave가 8bit를 받으면 다 받았다는 done신호를 내보내야함.
그럼 register에 write할지 read할지 그 signal 필요
addr, signal필요/ wdata, rdata도 필요
serial이다 보니 data를 하나씩 취합한 다음에 읽거나 쓰기 해야 함. 하지만 사용자 입장에서는 사용하기 편함 왜냐하면 연결할게 적기 때문.
따라서 1. 처음에 MSB를 write, read인지 확인하고 하위 2bit를 address로 사용
2. 그 다음에 들어오는 data를 wdata에 연결
write절차는 1번, 2번 두개면 충분
참고
Full duplex 원리
한 클럭 주기 안에 순차적으로 read와 write가 번갈아 일어나서
결과적으로는 매 클럭마다 송수신이 동시에 진행된 것과 같은 효과를 냄.
MOSI는 master가 받아온 tx_data를 1bit씩 내보내는 것
master가 SCLK를 생성해서 slave에게 주는데 SCLK가 falling edge일 때 MOSI를 주게 함
즉 falling edge를 기준으로 MOSI가 바뀜
master는 또한 slave가 준 data를 sampling하는데 sampling 타이밍은 SCLK의 rising edge임
이 때 하는 이유는 , 이 타이밍이 slave가 master에게 주는 data(MISO)의 중간 시점이기 때문.